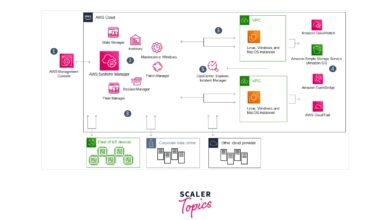
Ever wondered what happens when everything suddenly stops working? System failure isn’t just a glitch—it’s a full-blown crisis that can bring industries to their knees. From power grids to software networks, understanding its roots is the first step to resilience.


What Is System Failure? A Deep Dive into the Core Concept

At its most basic, a system failure occurs when a network, machine, software, or infrastructure stops performing its intended function. This can be temporary or permanent, localized or widespread. The term applies across industries—from IT and healthcare to transportation and energy.
Defining System Failure in Technical Terms
In engineering and computer science, a system failure is formally defined as the point at which a system can no longer meet its operational requirements. This could mean a server crashing, a power plant shutting down, or an aircraft’s navigation system malfunctioning. According to the International Organization for Standardization (ISO), system reliability is measured by mean time between failures (MTBF), a key metric in predicting and managing system failure risks.
- A system failure may result from hardware breakdown, software bugs, or human error.
- It often triggers a cascade effect, where one failure leads to others.
- The severity is classified based on impact: minor, major, or catastrophic.
Types of System Failures
Not all system failures are created equal. They can be categorized based on origin, scope, and duration:
- Hardware Failure: Physical components like hard drives, processors, or sensors stop working.
- Software Failure: Bugs, memory leaks, or unhandled exceptions crash applications.
- Network Failure: Connectivity loss due to router issues, cyberattacks, or signal interference.
- Human-Induced Failure: Mistakes in configuration, maintenance, or operation.
- Environmental Failure: Natural disasters like floods, fires, or electromagnetic pulses.
“A system is only as strong as its weakest link.” — This timeless engineering principle underscores why even small components can trigger massive system failure.
7 Major Causes of System Failure You Can’t Ignore
Understanding the root causes of system failure is crucial for prevention. Below are seven of the most common—and often overlooked—reasons systems collapse.
1. Poor Design and Engineering Flaws
One of the most insidious causes of system failure is flawed design. When systems are built without proper stress testing, redundancy, or fail-safes, they’re vulnerable from day one. The NASA Challenger disaster in 1986 is a tragic example—engineers knew the O-rings were vulnerable in cold weather, but the design flaw wasn’t addressed.
- Lack of redundancy in critical components.
- Inadequate load testing during development.
- Failure to account for edge cases in system behavior.
2. Software Bugs and Coding Errors
In the digital age, software is the backbone of nearly every system. A single line of faulty code can bring down entire networks. The 2012 Knight Capital Group incident saw a software glitch wipe out $440 million in 45 minutes due to an untested algorithm deployment.
- Uncaught exceptions leading to application crashes.
- Memory leaks that degrade performance over time.
- Concurrency issues in multi-threaded environments.
3. Cyberattacks and Security Breaches
Cyberattacks are a growing cause of system failure. Malware, ransomware, and distributed denial-of-service (DDoS) attacks can cripple systems by overwhelming them or encrypting critical data. The 2017 NotPetya attack caused over $10 billion in damages globally, shutting down ports, factories, and hospitals.
- Ransomware encrypting system files and demanding payment.
- Phishing leading to unauthorized access and data corruption.
- Zero-day exploits targeting unpatched vulnerabilities.
4. Hardware Degradation and Wear
Physical components degrade over time. Hard drives fail, capacitors leak, and sensors lose calibration. Predictive maintenance can mitigate this, but many organizations wait for failure before acting. The Amazon Web Services (AWS) outage in 2012 was caused by a failed cooling system in a data center, leading to server overheating and widespread service disruption.
- Thermal stress on electronic components.
- Power surges damaging circuitry.
- Lack of environmental controls in server rooms.
5. Human Error and Operational Mistakes
Humans are often the weakest link. A misconfigured firewall, accidental deletion of critical files, or incorrect system updates can all lead to system failure. In 2021, a single typo in a configuration file caused a Cloudflare outage that took down thousands of websites for 30 minutes.
- Incorrect command inputs in system consoles.
- Failure to follow standard operating procedures.
- Lack of training or oversight in technical teams.
6. Natural Disasters and Environmental Factors
Earthquakes, floods, hurricanes, and even solar flares can disrupt systems. In 2011, the Tōhoku earthquake and tsunami in Japan caused a nuclear disaster at Fukushima, where backup power systems failed, leading to meltdowns. Environmental resilience is now a key factor in system design.
- Flooding damaging underground data centers.
- Power grid collapse during extreme weather.
- Electromagnetic interference from solar storms.
7. Overload and Resource Exhaustion
Systems have limits. When demand exceeds capacity—like too many users hitting a website at once—system failure becomes inevitable. The 2020 Zoom outage during the pandemic surge was due to unprecedented traffic overwhelming their servers.
- CPU or memory saturation in servers.
- Bandwidth throttling or network congestion.
- Database timeouts under high query loads.
Real-World Examples of Catastrophic System Failure
History is littered with system failures that had far-reaching consequences. These cases offer critical lessons in risk management and system design.
The 2003 Northeast Blackout
One of the largest power outages in North American history affected 55 million people across the U.S. and Canada. The root cause? A software bug in an alarm system at FirstEnergy Corporation. When a transmission line failed, the system didn’t alert operators, leading to a cascading failure.
- Failure in the Energy Management System (EMS) software.
- Lack of real-time monitoring and response.
- Regulatory gaps in grid maintenance protocols.
The blackout lasted up to two days in some areas, costing an estimated $6 billion and exposing critical vulnerabilities in national infrastructure.
The Therac-25 Radiation Therapy Machine
Between 1985 and 1987, the Therac-25 medical device delivered lethal radiation doses to patients due to a software race condition. Six known accidents occurred, resulting in deaths and severe injuries. This case is now a staple in software engineering ethics courses.
- A race condition allowed unsafe mode transitions.
- Poor error messaging misled operators.
- Lack of hardware interlocks as a backup.
The Mars Climate Orbiter Disaster
In 1999, NASA lost a $125 million spacecraft because one team used metric units while another used imperial. The navigation system failure caused the orbiter to enter Mars’ atmosphere too low and disintegrate.
- Unit mismatch in trajectory calculations.
- Inadequate verification of data inputs.
- Failure in cross-team communication protocols.
How System Failure Impacts Different Industries
The consequences of system failure vary by sector, but the impact is almost always severe—financial, operational, and reputational.
Healthcare: When Lives Are on the Line
In hospitals, system failure can be fatal. Electronic health records (EHR) going down, ventilators malfunctioning, or lab systems failing can delay treatment and endanger patients. During the 2017 WannaCry ransomware attack, the UK’s NHS had to cancel thousands of appointments as systems were encrypted.
- Patient data inaccessibility during emergencies.
- Delays in diagnosis and treatment.
- Loss of trust in digital healthcare systems.
Finance: Billions at Risk
Banks and trading platforms rely on real-time data. A system failure can halt transactions, freeze accounts, or trigger market volatility. The 2012 NASDAQ Facebook IPO glitch delayed trading for 30 minutes, causing investor losses and a class-action lawsuit.
- Transaction rollbacks and data inconsistency.
- Regulatory fines for service disruption.
- Reputational damage affecting customer retention.
Transportation: From Delays to Disasters
Air traffic control systems, railway signaling, and autonomous vehicles all depend on flawless operation. In 2019, a software update caused Boeing 737 MAX planes to nosedive, leading to two crashes and 346 deaths. The MCAS system failure highlighted the dangers of over-reliance on automation without proper safeguards.
- Flight cancellations and scheduling chaos.
- Safety risks in automated systems.
- Massive financial losses for airlines and manufacturers.
Preventing System Failure: Best Practices and Strategies
While not all failures can be prevented, robust strategies can drastically reduce their frequency and impact.
Implement Redundancy and Failover Systems
Redundancy ensures that if one component fails, another takes over seamlessly. This is common in data centers with backup power supplies, mirrored databases, and redundant network paths.
- Use load balancers to distribute traffic across servers.
- Deploy RAID configurations for disk redundancy.
- Implement automatic failover for critical services.
Conduct Regular Testing and Simulations
Stress testing, penetration testing, and disaster recovery drills help identify weaknesses before they cause real-world failure. Companies like Google run “Chaos Monkey” experiments, where they randomly shut down servers to test resilience.
- Simulate cyberattacks to test response protocols.
- Perform load testing before product launches.
- Use sandbox environments for risky updates.
Adopt Proactive Monitoring and Alerting
Real-time monitoring tools like Nagios, Datadog, or Prometheus can detect anomalies before they escalate. Alerts should be configured for CPU usage, memory leaks, disk space, and network latency.
- Set up dashboards for system health visibility.
- Use AI-driven anomaly detection for early warnings.
- Integrate alerts with incident response teams.
The Role of AI and Machine Learning in Predicting System Failure
Artificial intelligence is revolutionizing how we anticipate and respond to system failure. By analyzing vast datasets, AI can predict hardware degradation, detect unusual network behavior, and even suggest preventive actions.
Predictive Maintenance Using AI
AI models analyze sensor data from machinery to predict when components will fail. For example, General Electric uses AI to monitor jet engines and schedule maintenance before breakdowns occur.
- Vibration analysis to detect bearing wear.
- Temperature trends indicating cooling issues.
- Predictive algorithms reducing unplanned downtime.
Anomaly Detection in Network Traffic
Machine learning models can establish a baseline of normal network behavior and flag deviations that may indicate a cyberattack or system strain. Tools like Darktrace use AI to identify zero-day threats in real time.
- Unusual login attempts or data exfiltration patterns.
- Sudden spikes in bandwidth usage.
- Behavioral analysis of user and device activity.
Legal and Ethical Implications of System Failure
When systems fail, questions of accountability arise. Who is responsible? The developer? The operator? The regulator?
Liability and Regulatory Compliance
Industries like healthcare and finance are bound by strict regulations (e.g., HIPAA, GDPR, SOX). A system failure that leads to data breaches can result in hefty fines and legal action. In 2018, British Airways was fined £183 million under GDPR after a breach exposed 500,000 customer records.
- Non-compliance with data protection laws.
- Failure to implement required security controls.
- Insufficient incident reporting and response.
Ethical Responsibility in System Design
Engineers and developers have a moral obligation to build safe, reliable systems. The Therac-25 case showed how cutting corners in software design can have deadly consequences. Ethical frameworks now emphasize “safety by design” principles.
- Transparency in algorithmic decision-making.
- Accountability for automated system behavior.
- Inclusive testing to avoid bias in AI systems.
“With great power comes great responsibility.” — This adage holds true for those who design the systems that power our world.
Building a Resilient Future: Lessons Learned from System Failure
The key to avoiding future system failures lies in learning from the past. Resilience isn’t about preventing every failure—it’s about designing systems that can withstand, adapt, and recover.
Cultivating a Culture of Reliability
Organizations must foster a culture where reliability is prioritized over speed. This means investing in training, encouraging reporting of near-misses, and rewarding proactive problem-solving.
- Encourage blameless post-mortems after incidents.
- Promote cross-functional collaboration.
- Invest in continuous learning and certification.
Designing for Failure from the Start
Modern system architecture, like microservices and cloud-native design, embraces the idea that failure is inevitable. Instead of avoiding it, systems are built to isolate and contain failures.
- Use circuit breakers to prevent cascading failures.
- Implement graceful degradation under load.
- Design stateless services for easier recovery.
The Future of System Reliability
As technology grows more complex, so must our approaches to reliability. Quantum computing, AI-driven automation, and interconnected IoT devices will require new standards, tools, and mindsets to prevent system failure at scale.
- Development of self-healing systems.
- Global standards for AI safety and ethics.
- Increased investment in cybersecurity infrastructure.
What is the most common cause of system failure?
The most common cause of system failure is human error, followed closely by software bugs and hardware degradation. According to a Gartner study, over 70% of outages are linked to changes in systems—often made by administrators or developers.
How can organizations prevent system failure?
Organizations can prevent system failure by implementing redundancy, conducting regular testing, using real-time monitoring, and fostering a culture of reliability. Proactive maintenance and employee training are also critical.
What is the difference between system failure and system error?
A system error is a temporary malfunction that may be resolved without intervention, while a system failure means the system has stopped functioning entirely and requires repair or restart. All system failures begin with errors, but not all errors lead to failure.
Can AI completely prevent system failure?
No, AI cannot completely prevent system failure, but it can significantly reduce the risk by predicting issues, detecting anomalies, and automating responses. Human oversight remains essential.
What should be done immediately after a system failure?
After a system failure, organizations should activate their incident response plan, isolate the affected systems, communicate with stakeholders, diagnose the root cause, and begin recovery procedures. A post-mortem analysis should follow to prevent recurrence.
System failure is not just a technical issue—it’s a systemic challenge that spans engineering, human behavior, and organizational culture. From the Therac-25 tragedy to modern cyberattacks, the lessons are clear: reliability must be designed in, not added later. By understanding the causes, learning from past mistakes, and embracing technologies like AI and redundancy, we can build systems that are not just powerful, but resilient. The future depends on it.
Further Reading: