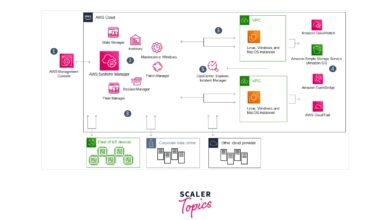
Ever wondered what happens behind the scenes when your computer runs? System logs hold the answers—silent witnesses to every action, error, and event in your digital environment. These records are more than just technical jargon; they’re essential tools for security, troubleshooting, and performance optimization.


What Are System Logs and Why They Matter

System logs are chronological records generated by operating systems, applications, and network devices that document events occurring within a computing environment. They capture everything from user logins and software crashes to hardware failures and security breaches. These logs serve as a digital diary for IT systems, offering visibility into system behavior over time.
The Core Purpose of System Logs
At their heart, system logs exist to provide accountability, traceability, and insight. When something goes wrong—like a server crash or unauthorized access—system logs are often the first place administrators look. They help answer critical questions: Who did what? When did it happen? And how did it occur?
- Enable real-time monitoring of system health
- Support forensic investigations after security incidents
- Facilitate compliance with regulatory standards like GDPR or HIPAA
“Without system logs, troubleshooting is like navigating in the dark—possible, but unnecessarily risky.” — IT Operations Expert
Types of Events Captured in System Logs
System logs don’t just record errors—they log a wide spectrum of activities. Common event types include:
- Informational messages: Routine operations such as service startups or successful backups.
- Warning events: Potential issues that don’t immediately disrupt service but may require attention (e.g., low disk space).
- Error logs: Failures in processes, like failed file access or application crashes.
- Critical alerts: Severe problems such as system shutdowns or hardware malfunctions.
- Security-related events: Login attempts (successful or failed), privilege escalations, and policy changes.
Each entry typically includes a timestamp, source (e.g., application name), event ID, and a descriptive message. This metadata makes system logs invaluable for diagnosing complex issues across distributed environments.
How System Logs Work Across Different Platforms
Different operating systems and platforms manage system logs in unique ways. Understanding these differences is crucial for effective log management and analysis.
Windows Event Logs: Structure and Access
On Windows systems, system logs are managed through the Event Viewer, which organizes logs into three primary categories: Application, Security, and System. Each log type serves a distinct function:
- Application Log: Records events logged by programs, such as database errors or service failures.
- Security Log: Tracks authentication attempts, account management, and audit policies (requires auditing to be enabled).
- System Log: Contains events generated by Windows system components, like driver failures or service startups.
Advanced features like filtering, custom views, and remote log collection make Windows Event Logs a robust tool for enterprise environments. For deeper insights, administrators can use PowerShell scripts or tools like Microsoft’s Event Log API to automate log analysis.
Linux Syslog and Journalctl: The Backbone of Unix Logging
In Linux and Unix-based systems, the traditional logging system revolves around syslog, a standard for message logging. Most distributions use rsyslog or syslog-ng as the daemon responsible for collecting and routing log messages.
Modern Linux systems, especially those using systemd, rely on journalctl—a powerful command-line utility that interfaces with the systemd journal. Unlike traditional text-based logs, journalctl stores structured binary data, enabling richer querying capabilities.
- View all logs:
journalctl - Filter by service:
journalctl -u nginx.service - Show recent errors:
journalctl -p err..alert - Monitor in real-time:
journalctl -f
The systemd journal integrates seamlessly with other system components and supports persistent logging when configured. For more details, refer to the official journalctl documentation.
macOS Unified Logging System
Apple introduced the Unified Logging System (ULS) with macOS Sierra (10.12) to replace the older ASL (Apple System Log) framework. ULS improves performance and reduces disk usage by compressing logs and storing them in a binary format.
Logs are accessed via the log command in Terminal. Key commands include:
log show --last 1h: Displays logs from the past hourlog stream --predicate 'subsystem == "com.apple.airplay"': Live stream of AirPlay-related eventslog stats: Provides summary statistics about log volume and sources
ULS also integrates with Console.app, offering a graphical interface for browsing logs. Due to privacy enhancements, some logs are obfuscated or require elevated privileges to view, aligning with Apple’s focus on user data protection.
The Critical Role of System Logs in Cybersecurity
In today’s threat landscape, system logs are a frontline defense mechanism. They enable early detection of malicious activity, support incident response, and assist in post-breach analysis.
Detecting Intrusions Through Log Analysis
Cyber attackers often leave digital footprints in system logs. Unusual login times, repeated failed authentication attempts, or unexpected process executions can signal a compromise. For example, a series of failed SSH login attempts followed by a successful one from an unfamiliar IP address could indicate a brute-force attack.
Security Information and Event Management (SIEM) systems like Splunk, IBM QRadar, or Elastic Security aggregate system logs from multiple sources and apply correlation rules to detect anomalies. These platforms use machine learning and behavioral analytics to distinguish normal activity from potential threats.
- Monitor for lateral movement indicators (e.g., remote desktop connections between internal hosts)
- Track privilege escalation events (e.g., use of
sudoorsucommands) - Identify persistence mechanisms (e.g., new scheduled tasks or startup entries)
According to the CISA Log Management Guide, maintaining comprehensive system logs is a foundational practice for cybersecurity resilience.
Forensic Investigations and Chain of Custody
After a security incident, system logs become legal evidence. To ensure admissibility in court, organizations must maintain the integrity and authenticity of log data. This involves implementing secure logging practices such as:
- Centralized log collection to prevent tampering
- Immutable log storage (e.g., write-once-read-many media)
- Hashing and digital signatures to verify log integrity
- Accurate time synchronization using NTP (Network Time Protocol)
“Logs are the breadcrumbs that lead investigators back to the origin of an attack.” — Digital Forensics Analyst
During forensic analysis, experts reconstruct timelines using timestamps from multiple log sources. Discrepancies in time settings across devices can distort this timeline, emphasizing the need for precise clock synchronization.
Compliance and Regulatory Requirements
Many industries are legally required to retain system logs for a specified period. Regulations such as the General Data Protection Regulation (GDPR), Health Insurance Portability and Accountability Act (HIPAA), and Payment Card Industry Data Security Standard (PCI DSS) mandate logging and monitoring practices.
- GDPR: Requires logging of data access and processing activities to demonstrate accountability.
- HIPAA: Mandates audit trails for all access to electronic protected health information (ePHI).
- PCI DSS: Specifies that system logs must be retained for at least one year, with a minimum of three months immediately available for analysis.
Failure to comply can result in hefty fines and reputational damage. Organizations must therefore implement policies for log retention, access control, and regular review.
Best Practices for Managing System Logs
Effective log management goes beyond simply collecting data. It involves strategic planning, proper tooling, and ongoing maintenance to ensure logs remain useful and secure.
Centralized Logging with SIEM and Log Aggregators
In modern IT environments, logs are generated across hundreds or thousands of devices. Centralizing these system logs into a single platform simplifies monitoring and analysis. Tools like:
- Splunk: Offers powerful search, visualization, and alerting capabilities.
- Elastic Stack (ELK): Combines Elasticsearch, Logstash, and Kibana for scalable log management.
- Graylog: Open-source alternative with strong alerting and extraction features.
- Fluentd: Cloud-native data collector that supports structured logging.
These platforms ingest logs via agents (e.g., Filebeat, Winlogbeat) or network protocols (e.g., Syslog, SNMP). Once centralized, logs can be indexed, searched, and visualized in real time. For instance, Filebeat efficiently ships log files from servers to Elasticsearch.
Log Rotation and Retention Policies
Unmanaged logs can quickly consume disk space and degrade system performance. Log rotation addresses this by automatically archiving or deleting old logs based on size or age.
On Linux systems, logrotate is the standard utility for managing this process. A typical configuration might look like:
/var/log/nginx/*.log {
daily
missingok
rotate 14
compress
delaycompress
notifempty
create 0640 www-data adm
}
This script rotates Nginx logs daily, keeps 14 backups, compresses them, and creates new log files with appropriate permissions.
Retention policies should align with business needs and compliance requirements. While some logs may be kept for years, others can be purged after 30 days. Always document your retention strategy and ensure backups are stored securely.
Securing System Logs from Tampering
Attackers often attempt to erase or alter system logs to cover their tracks. To prevent this, organizations must implement protective measures:
- Send logs to a remote, dedicated log server that is not accessible to regular users.
- Use Transport Layer Security (TLS) to encrypt log transmission.
- Enable log integrity checking using tools like AIDE (Advanced Intrusion Detection Environment).
- Restrict read and write access to log files using strict file permissions (e.g.,
chmod 640 /var/log/*.log).
Immutable logging solutions, such as those offered by cloud providers (e.g., AWS CloudTrail with S3 Object Lock), ensure logs cannot be deleted or modified, even by administrators.
Common Challenges in System Log Management
Despite their importance, managing system logs presents several challenges that can hinder their effectiveness.
Log Volume and Noise
Modern systems generate massive amounts of log data—sometimes terabytes per day in large enterprises. This volume can overwhelm storage systems and make it difficult to identify meaningful events.
Moreover, many logs are low-value “noise,” such as routine status updates. Without proper filtering and prioritization, critical alerts can get buried in irrelevant data.
- Implement log filtering at the source to reduce unnecessary entries.
- Use AI-driven anomaly detection to highlight unusual patterns.
- Apply log level thresholds (e.g., only collect warnings and above in production).
According to a Gartner report, over 60% of organizations struggle with log overload, leading to delayed threat detection.
Inconsistent Log Formats
Logs from different applications and vendors often use inconsistent formats, making aggregation and analysis difficult. One system might use JSON, another plain text, and a third a custom binary format.
To address this, normalization is key. Tools like Logstash or Fluentd can parse incoming logs and convert them into a standardized schema (e.g., Common Event Format or JSON). This enables consistent querying and correlation across systems.
- Define a common log schema for internal applications.
- Use structured logging libraries (e.g.,
structlogin Python). - Leverage OpenTelemetry for unified telemetry data collection.
Time Synchronization Issues
Accurate timestamps are crucial for correlating events across systems. If servers have unsynchronized clocks, it becomes nearly impossible to reconstruct attack timelines or diagnose distributed system failures.
Network Time Protocol (NTP) is the standard solution for synchronizing clocks across networks. Best practices include:
- Configure all systems to use reliable NTP servers (e.g.,
pool.ntp.org). - Monitor NTP offset and jitter regularly.
- Use Precision Time Protocol (PTP) in high-frequency trading or industrial control systems where microsecond accuracy is needed.
Even a few seconds of drift can lead to misinterpretation of event sequences, especially in security investigations.
Advanced Tools and Technologies for System Logs
As system complexity grows, so do the tools available for log management and analysis. Modern solutions offer automation, intelligence, and scalability.
AI and Machine Learning in Log Analysis
Artificial intelligence is transforming how we interpret system logs. Instead of relying solely on predefined rules, AI models can learn normal behavior and flag deviations.
For example, unsupervised learning algorithms can cluster similar log messages and detect rare patterns that might indicate a zero-day exploit. Natural Language Processing (NLP) techniques help parse unstructured log messages and extract meaningful entities like IP addresses, usernames, or error codes.
- Use cases include anomaly detection, root cause analysis, and predictive maintenance.
- Platforms like Datadog, Sumo Logic, and Microsoft Sentinel incorporate AI-driven insights.
- Challenges include model training data quality and false positive rates.
A 2020 IEEE study demonstrated that ML-based log analysis reduced mean time to detect (MTTD) security incidents by up to 70%.
Cloud-Native Logging with Kubernetes and Serverless
In cloud environments, especially those using containers and microservices, traditional logging approaches fall short. Dynamic workloads mean pods and functions come and go rapidly, making log collection challenging.
Kubernetes, for instance, treats logs as ephemeral streams. Each pod writes logs to stdout/stderr, which are then collected by agents like Fluent Bit or Logstash. These logs are typically forwarded to a central backend like Elasticsearch or Google Cloud Logging.
- Use sidecar containers to ship logs from application pods.
- Leverage Kubernetes labels and annotations for log routing.
- Implement log aggregation at the node level using DaemonSets.
For serverless architectures (e.g., AWS Lambda), logs are automatically sent to cloud-native services like CloudWatch Logs. However, the lack of persistent storage means developers must design for log retention and querying from the start.
Open Standards and Interoperability
Interoperability between logging tools and platforms is improving thanks to open standards. Initiatives like:
- Common Event Format (CEF): Developed by ArcSight, widely supported by SIEMs.
- Log Data Format (LDF): A flexible schema for representing log entries.
- OpenTelemetry: A CNCF project providing a unified API for metrics, traces, and logs.
These standards reduce vendor lock-in and enable seamless integration across hybrid environments. OpenTelemetry, in particular, is gaining traction as a future-proof solution for observability.
Future Trends in System Logs and Observability
The field of system logs is evolving rapidly, driven by cloud computing, AI, and the growing demand for real-time insights.
From Reactive to Proactive Monitoring
Traditionally, system logs were used reactively—reviewed after an incident occurred. Now, organizations are shifting toward proactive monitoring, where logs feed into predictive models that anticipate failures before they happen.
For example, analyzing historical log patterns can reveal early signs of disk degradation or memory leaks. By setting up predictive alerts, teams can perform maintenance during scheduled windows rather than responding to outages.
- Combine logs with metrics and traces for full-stack observability.
- Use machine learning to forecast resource exhaustion.
- Integrate with ITSM tools to auto-create tickets based on log anomalies.
The Rise of Observability Platforms
Observability goes beyond traditional monitoring by enabling deep understanding of system behavior through logs, metrics, and traces (the “three pillars”). Modern platforms like New Relic, Dynatrace, and Grafana Loki provide unified interfaces for exploring all three data types.
Grafana Loki, for instance, is designed specifically for log aggregation and excels at label-based querying. It integrates tightly with Prometheus (metrics) and Tempo (traces), creating a cohesive observability stack.
- Observability enables faster root cause analysis in complex systems.
- It supports developer self-service, reducing dependency on ops teams.
- Provides context-rich dashboards that link logs to specific transactions.
Privacy and Ethical Considerations
As logging becomes more pervasive, concerns about user privacy and data ethics grow. Logs may inadvertently capture sensitive information like passwords, personal identifiers, or health data.
To mitigate risks:
- Implement log masking or redaction for sensitive fields.
- Conduct regular audits to ensure compliance with privacy policies.
- Adopt a data minimization principle—only collect what’s necessary.
Organizations must balance security needs with ethical responsibilities, ensuring transparency and accountability in how system logs are used.
What are system logs used for?
System logs are used for monitoring system health, diagnosing technical issues, detecting security threats, ensuring regulatory compliance, and conducting forensic investigations after incidents. They provide a detailed record of events that helps IT teams maintain stability and security.
How long should system logs be kept?
Retention periods vary by industry and regulation. Generally, logs should be kept for at least 30–90 days for operational purposes. Compliance standards like PCI DSS require retention for one year, with three months readily accessible. Always align retention policies with legal and business requirements.
Can system logs be faked or tampered with?
Yes, system logs can be altered by attackers with sufficient access. To prevent tampering, organizations should use centralized, immutable logging solutions, encrypt log transmission, restrict access, and employ integrity-checking tools like AIDE or blockchain-based audit trails.
What is the difference between logs and events?
An “event” is a single occurrence in a system (e.g., a user login). A “log” is the recorded entry that documents that event. Logs are collections of events stored in a structured format for later analysis.
Which tools are best for analyzing system logs?
Popular tools include Splunk, Elastic Stack (ELK), Graylog, Datadog, and Grafana Loki. For security-focused analysis, SIEM platforms like IBM QRadar, Microsoft Sentinel, and AlienVault USM are widely used. The best choice depends on scale, budget, and technical requirements.
System logs are far more than technical artifacts—they are vital components of modern IT infrastructure. From troubleshooting everyday glitches to defending against sophisticated cyberattacks, they provide the visibility needed to keep systems running smoothly and securely. As technology evolves, so too will the methods for collecting, analyzing, and leveraging these records. By adopting best practices in log management, embracing advanced tools, and staying ahead of emerging trends, organizations can turn system logs into a strategic asset. Whether you’re a system administrator, security analyst, or developer, understanding system logs is no longer optional—it’s essential.
Further Reading: